Seznam témat:
Popis
Distribuované zpracování dat je sice levný způsob sdílení dat mezi dvěma a více pobočkami, ale klade obrovské nároky na nastavení celého systému a především na udržení uživatelské kázně. Pro jednoduchost předpokládejme případ dvou místně odloučených provozoven se základním požadavkem sdílení veškerých dat. Protože místa nejsou trvale propojena, je nezbytně nutné, aby byla kompletní data na obou místech. Je zřejmé, že v před zahájením práce musí být obě databáze zcela identické. V okamžiku, kdy začnou uživatelé pořizovat data do každé z databází, začnou vznikat mezi databázemi rozdíly. Systém v tzv. transakčním logu kontroluje veškeré tyto změny. V pravidelných intervalech se mohou obě databáze propojit a tyto změny si vzájemně vyměnit. Po uskutečnění výměny jsou databáze opět zcela identické.
Jak je to zajištěno
Předávání dat mezi databázemi je nutno zajistit na dvou úrovních ( hardwarově systémová úroveň, databázová úroveň)
Hardwarově systémová úroveň
Výhodou tohoto systému je, že nepotřebuje trvalé spojení mezi místně odloučenými místy. Přesto je potřeba někde schraňovat všechny vzniklé rozdíly a nějak je dopravit do vedlejší databáze a opačně přijmout rozdíly z vedlejší databáze. Nejoptimálnějším postupem se v tomto okamžiku jeví využití služeb FTP serveru. FTP server může být připojen libovolným způsobem (vyhrazená linka, internet, vytáčená ISDN přípojka a podobně). FTP server může být fyzicky umístěn na libovolném místě s tou podmínkou, aby se k němu mohly připojit obě databáze. Obvykle se to řeší tak, že FTP server je umístěn na jedné z lokálních sítí, takže jedna z databází k němu má přístup okamžitě a druhá se připojuje prostřednictvím nějakého spojení (ISDN, internet atd..).
Databázová úroveň
Na úrovni databázové je zaznamenávána každá změna od posledního zaregistrovaného přenosu dat (replikace). Jakmile je vyvolán přenos (je spuštěn agend DbRemote s patřičnými parametry), jsou kontrolovány tzv. publikační skripty (to je definice toho, co se má přenášet a kam) a na jejich základě se vytvoří "balíček" pro ostatní databáze. Tento balíček je agentem "DbRemote" umístěna na FTP serveru v předem připraveném adresáři a opačně jsou odtud vyzvednuty balíčky, které jsou určeny pro tuto databázi. Příchozí balíček je dekódován a formou SQL příkazů je data přijata.
Jaké podmínky je nutno stanovit
Z výše uvedeného je patrné, že systém je velice dobře zranitelný. Největší nebezpečí spočívá v tom, co je obecně považováno za jednu z největších předností SQL databáze. SQL databáze je obecně "relační" a bude za každých okolností trvat na tom, aby relace nebyly porušeny. Druhé nebezpečí vzniká nespolehlivou funkcí přenosového kanálu. Je lhostejné, jaký typ přenosu je použit, ale v okamžiku, kdy databáze nemůže uskutečnit z jakéhokoliv důvodu přenos se výrazně zvyšuje pravděpodobnost selhání celého systému s následným rozsynchronizováním databáze. Třetí velké nebezpečí plyne ze samotné logiky místně odděleného zpracování dat. Uveďme několik příkladů možnosti selhání replikací:
a / Uživatel 1(U1) v místě 1 (Db1) vystaví fakturu s číslem 02000001 . Ve stejný den Uživatel 2 (U2) v místě 2 (Db2) pořídí také fakturu ale protože U2 neví, že U1 fakturu s číslem 02000001 vystavil, vystaví také fakturu s číslem 02000001. V noci dojde k replikaci dat mezi Db1 a Db2 přenos selže na tzv. replikačním konfliktu, protože v systému může být pouze jedna faktura s číslem 02000001 a nebude vědět, která faktura je ta pravá.
b/ Uživatel U1 se rozhodne opravit účetní doklad 03000001 stejný den udělá totéž uživatel U2. V okamžiku replikací bude systém opět řešit problém, která oprav je ta pravá a nepřenese ani jednu - vznikne replikační konflikt (chyba).
Řešení je pro takové případy pouze jedno jediné. Každé odloučené místo musí mít vlastní řadu (nebo ještě lépe knihu) dokladů, do kterých bude data pořizovat a ve kterých bude provádět jakékoliv korekce a opravy. Je naprosto nepřípustné, aby dva uživatelé z různých míst opravovali týž doklad. Korekce je proto nutné dělat pouze v místě vzniku dokladu nebo jinými opravnými doklady (a opět ve speciálních řadách pro jednotlivá místa). Jakékoliv porušení tohoto pravidla vede dříve nebo později ke kolapsu replikačního systému.
c/ V obou databázích existuje kontakt na obchodního partnera s ičem 123 (F123). Uživatel U1 na Db1 vystaví svou první fakturu (04000001) tomuto partnerovi. Ten samý den uživatel U2 provádí kontrolu své databáze Db2 a rozhodne se, že záznam F123, na který doposud neexistuje žádná vazba z databáze z jakéhokoliv důvodu vymaže. V noci se servery spojí. Databáze Db1 se pokusí předat databázi Db2 fakturu 04000001. Tato faktura má však vazbu na firmu F123 a ta se z Db1 do Db2 nepřenáší, protože se s ní nic nedělo. V Db2 ale už tato firma není, protože ji uživatel U2 předtím vymazal. Databáze Db2 však zajišťuje relační integritu a proto fakturu 04000001 nepřijme, protože by faktura byla navázaná na neexistující záznam o F123. Replikace tak selže a vzniká zásadní rozdíl mezi oběma databázemi.
Řešení tohoto konfliktu je opět velmi striktní a důležité. Přístupovými právy a poučením uživatelů je nutné zajistit, aby uživatelé neměnili či nemazali primární klíče v tabulkách, na které se mohou odkazovat přenášené doklady (replikovaná data).
Z uvedeného tedy plynou základní obecná pravidla provozu replikačního systému:
A. Uživatel musí zajistit, aby v době mezi dvěma replikacemi nemohl na dvou a více místech vzniknout nový záznam se stejným primárním klíčem.
B. Uživatel musí zajistit, aby v době mezi dvěma replikacemi nemohl na dvou a více místech vzniknout update záznamu se stejným primárním klíčem.
C. Uživatel musí zajistit, aby se v době mezi dvěma replikacemi nemohl použít v replikovaném záznamu cizí klíč, který ve vedlejší databázi v okamžiku replikace chybí.
Tyto pravidla v praxi znamenají například toto:
ad A. Dva uživatelé na různých místech nesmí pořizovat doklady do stejné řady, jednoduše proto, aby se nepotkali v čísla dokladu. To platí u všech typů účetních dokladů, u objednávek přijatých i vydaných, u výrobních příkazů a podobně. Stejně tak to platí v případě společných číselníků jako je číselník firem, dokladových řad, souvztažností, zakázek, členění, materiálových karet, karet majetku, osobních čísel zaměstnanců a podobně.
ad B. Dva uživatelé na různých místech nesmí v opravovat záznamy ve stejných řadách, nebo ve stejných číselnících. Mělo by být zajištěno, aby se doklady opravovaly obecně v místě vzniku tohoto dokladu a číselníky aby se udržovali z jednoho místa.
ad C. Uživatel nesmí bez rozmyslu smazat nebo upravit záznam, ze kterého by mohl být na vedlejší databázi použit cizí klíč. V té souvislosti je velmi nebezpečné obvykle mazání firem z číselníku firem nebo hromadná změna IČa firmy. Totéž platí o číselníku materiálu, členění a podobně.
Pro zajištění těchto pravidel a především pro zajištění údržby číselníků z jednoho místa je nutno speciálně chránit tyto tabulky. Ideálním řešením je poskytnou práva upravovat, mazat a přidávat do těchto tabulek jen jednomu řádně poučenému uživateli.
Obecné řešení replikací pomocí Remote Database na databázi ASA vychází z hvězdicové architektury přenosu dat. Systém tedy předpokládá existenci jedné centrální databáze (tzv. konsolidované databáze) a několika vzdálených databází (Remote databází). Spojení je potom realizováno pouze mezi kteroukoliv Remote databází (R Db) a konsolidovanou databází (Kon Db).
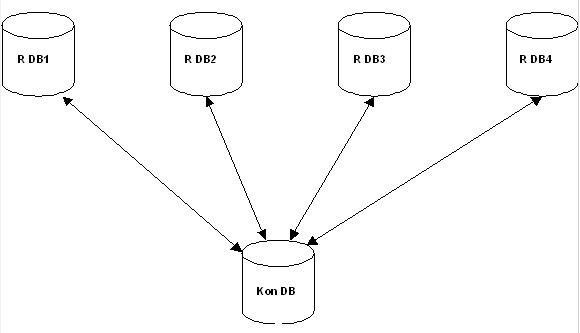
Tato struktura může být podstatně složitější, protože Kon Db může být jednou z několika dalších Remote databází pro vyšší konsolidovanou databázi. Tato architektura má tu přednost, že pro replikace se definují pouze publikace každé RDb do KonDb a pokud potřebujete selektivní distribuci dat, stačí na KonDb nastavit publikace do jednotlivých RDb podle vlastních pravidel. Je takto dovolen případ aby RDBn byly podmnožinou KonDb. Přesto je třeba stále zachovávat výše popsaná obecná pravidla.
Pro speciální případy, ve kterých má uživatel dvě pobočky a potřebuje zajistit identická data na obou z nich se zavádí replikační systém též s využitím konsolidované databáze a architektura vypadá takto:
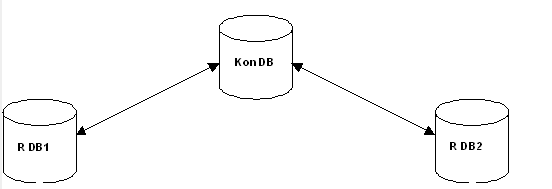
Konsolidovaná a jedna z Remote databází potom obvykle leží na jednom serveru a druhá Rdb se připojuje. KonDb zde potom plní funkci prostředníka mezi oběma databázemi RDb a obvykle se na ní přímo nepracuje. Zato se obvykle používá k vyhodnocování dat. Pomocí publikací se potom dá zajistit to, že obě RDb jsou identické, nebo naopak to, že se přenáší jen podstatné záznamy a nereplikují se různá uživatelská nastavení některé samostatně stojící číselníky, parametry a podobně. To je nejčastější příklad.
V rámci dodržení základních pravidel může společnost Vision Praha (dále jen zhotovitel) nastavit publikace libovolným způsobem, je to však placená služba včetně relativně dlouhého a náročného odladění nových publikací. Úspěšné zvládnutí replikačního systému předpokládá velmi účinnou spolupráci objednatele se zhotovitelem, především na straně testování, zajištění uživatelské kázně a dalších činnostech, které může objednatel zajistit. Nedodržením některého z doporučení se uživatel vystavuje nebezpečí ztráty dat a zhotovitel v takových případech odmítá vzít odovědnost za takto vzniklé škody.
Související témata.